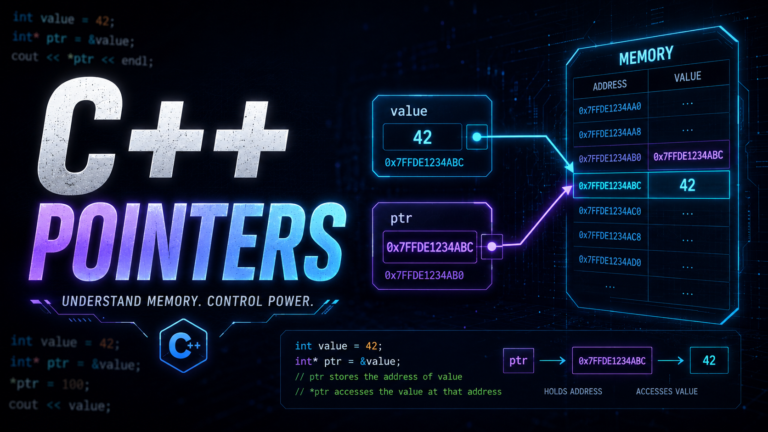
C++ unordered_map & unordered_set: Hash Table Containers Guide
Table of Contents
Why Unordered Containers?
While map and set provide O(log n) operations using balanced trees, unordered_map and unordered_set use hash tables for O(1) average-case lookups, insertions, and deletions. The tradeoff: elements are not sorted. If you don’t need sorted iteration or range queries, unordered containers are typically faster — especially as data grows large.
They live in <unordered_set> and <unordered_map> and were introduced in C++11. The API mirrors set/map closely, so switching between them requires minimal code changes.
std::unordered_set
#include <unordered_set>
#include <iostream>
#include <string>
int main() {
// Construction
std::unordered_set<int> numbers = {5, 2, 8, 1, 9, 3};
// Order is implementation-defined — NOT sorted
// Insert — O(1) average
numbers.insert(4);
numbers.emplace(7);
// Lookup — O(1) average
if (numbers.count(5)) {
std::cout << "5 exists\n";
}
if (numbers.contains(8)) { // C++20
std::cout << "8 exists\n";
}
auto it = numbers.find(3);
if (it != numbers.end()) {
std::cout << "Found: " << *it << "\n";
}
// Erase — O(1) average
numbers.erase(2);
numbers.erase(numbers.find(9));
// Iteration — order is unpredictable
for (int n : numbers) {
std::cout << n << " ";
}
std::cout << "\n";
// String set
std::unordered_set<std::string> words = {"hello", "world", "foo"};
words.insert("bar");
std::cout << words.size() << "\n"; // 4
}std::unordered_map
#include <unordered_map>
#include <iostream>
#include <string>
int main() {
// Construction
std::unordered_map<std::string, int> ages = {
{"Alice", 30}, {"Bob", 25}, {"Charlie", 35}
};
// operator[] — same behavior as std::map (inserts if missing!)
ages["Diana"] = 28; // insert
ages["Alice"] = 31; // overwrite
int unknown = ages["Eve"]; // INSERTS Eve with value 0!
// Safe access
auto it = ages.find("Bob");
if (it != ages.end()) {
std::cout << it->first << ": " << it->second << "\n";
}
// .at() throws on missing key
try {
int age = ages.at("Frank");
} catch (const std::out_of_range&) {
std::cout << "Frank not found\n";
}
// insert_or_assign (C++17)
ages.insert_or_assign("Alice", 32);
// try_emplace (C++17) — only inserts, never overwrites
ages.try_emplace("Alice", 99); // ignored — Alice exists
std::cout << ages["Alice"] << "\n"; // still 32
// Iteration — unordered
for (const auto& [name, age] : ages) {
std::cout << name << ": " << age << "\n";
}
// Erase
ages.erase("Eve");
std::cout << "Size: " << ages.size() << "\n";
}How Hash Tables Work
A hash table works by computing a hash value for each key, then using that value to determine which bucket stores the element. The process is:
// Conceptual hash table internals:
//
// 1. Hash the key: hash("Alice") → 2840912837
// 2. Compute bucket: 2840912837 % bucket_count → bucket 5
// 3. Search bucket 5: Linear scan of bucket's chain
//
// Buckets:
// [0] → empty
// [1] → {"Bob", 25}
// [2] → empty
// [3] → {"Charlie", 35} → {"Diana", 28} // collision!
// [4] → empty
// [5] → {"Alice", 30}
//
// Collisions: Multiple keys hash to the same bucket.
// Resolved by chaining (linked list in each bucket).
// The standard provides std::hash for built-in types:
#include <functional>
std::hash<int> int_hash;
std::hash<std::string> str_hash;
std::cout << int_hash(42) << "\n"; // some large number
std::cout << str_hash("hello") << "\n"; // some large number
std::cout << str_hash("hello") << "\n"; // same number — deterministicWhen a bucket has too many elements (high load factor), the table rehashes: it allocates more buckets and redistributes all elements. This is O(n) but happens rarely, keeping the amortized cost at O(1).
Bucket Interface
std::unordered_map<std::string, int> m = {
{"a", 1}, {"b", 2}, {"c", 3}, {"d", 4}, {"e", 5}
};
// Bucket count and load factor
std::cout << "Buckets: " << m.bucket_count() << "\n";
std::cout << "Size: " << m.size() << "\n";
std::cout << "Load factor: " << m.load_factor() << "\n";
std::cout << "Max load factor: " << m.max_load_factor() << "\n";
// Which bucket is a key in?
std::cout << ""a" is in bucket: " << m.bucket("a") << "\n";
// How many elements in a specific bucket?
for (size_t i = 0; i < m.bucket_count(); ++i) {
std::cout << "Bucket " << i << ": " << m.bucket_size(i) << " elements\n";
}
// Iterate within a single bucket
size_t b = m.bucket("a");
for (auto it = m.begin(b); it != m.end(b); ++it) {
std::cout << it->first << ": " << it->second << "\n";
}
// Control rehashing
m.max_load_factor(0.5); // rehash when load exceeds 50%
m.rehash(100); // ensure at least 100 buckets
m.reserve(1000); // pre-allocate for 1000 elementsCustom Hash Functions
std::hash is defined for built-in types and std::string. For user-defined types, you must provide a hash function:
#include <unordered_set>
#include <unordered_map>
#include <string>
struct Point {
int x, y;
bool operator==(const Point&) const = default; // C++20
};
// Method 1: Specialize std::hash
template<>
struct std::hash<Point> {
std::size_t operator()(const Point& p) const noexcept {
auto h1 = std::hash<int>{}(p.x);
auto h2 = std::hash<int>{}(p.y);
// Combine hashes — simple but effective
return h1 ^ (h2 << 32) ^ (h2 >> 32);
}
};
// Now usable directly
std::unordered_set<Point> points;
points.insert({1, 2});
points.insert({3, 4});
// Method 2: Custom hash functor
struct PointHash {
std::size_t operator()(const Point& p) const noexcept {
return std::hash<int>{}(p.x) * 31 + std::hash<int>{}(p.y);
}
};
struct PointEqual {
bool operator()(const Point& a, const Point& b) const {
return a.x == b.x && a.y == b.y;
}
};
std::unordered_set<Point, PointHash, PointEqual> point_set;
std::unordered_map<Point, std::string, PointHash, PointEqual> point_map;
// Method 3: Lambda hash (C++20 cleaner)
auto hash_fn = [](const Point& p) {
return std::hash<int>{}(p.x) ^ (std::hash<int>{}(p.y) << 16);
};
std::unordered_set<Point, decltype(hash_fn)> ps(10, hash_fn);A good hash function distributes keys uniformly across buckets. Poor hash functions cause many collisions, degrading O(1) to O(n). The XOR-shift-combine pattern shown above works well for most cases. For production code, consider using a proven hash combiner like Boost’s hash_combine.
Performance Tuning
// Pre-allocate when you know the size
std::unordered_map<int, int> large_map;
large_map.reserve(100000); // avoids rehashing during insertion
// Tune load factor for speed vs memory
// Lower load factor → fewer collisions → faster lookup → more memory
large_map.max_load_factor(0.5); // aggressive — fast but uses more RAM
// Higher load factor → more collisions → slower lookup → less memory
large_map.max_load_factor(2.0); // compact but slower
// Default is 1.0 — good balance
// Benchmark: unordered_map vs map for lookup-heavy workload
// For 1M elements:
// unordered_map.find(): ~50ns (O(1))
// map.find(): ~500ns (O(log n), n=1M → ~20 comparisons)
// 10x faster for pure lookups!
// But for small maps (< 100 elements):
// Sorted vector + binary_search can beat both due to cache localityUnordered vs Ordered
Choosing between map/set and unordered_map/unordered_set:
Use unordered_map/unordered_set when: You need the fastest possible lookups. You don't need sorted iteration. You don't need range queries (lower_bound/upper_bound). Your key type has a good hash function.
Use map/set when: You need elements in sorted order. You need range queries (all keys between X and Y). You need deterministic iteration order. Your key type doesn't have a natural hash function but has operator<. Worst-case O(log n) is more important than average-case O(1) — hash tables can degrade to O(n) with many collisions.
Use neither when: Your dataset is small (under ~100 elements). A sorted vector with std::lower_bound often beats both due to contiguous memory and cache friendliness.
Real-World Examples
#include <unordered_map>
#include <unordered_set>
#include <string>
#include <vector>
#include <iostream>
// Two-sum problem — classic interview question
std::vector<int> two_sum(const std::vector<int>& nums, int target) {
std::unordered_map<int, int> seen; // value → index
for (int i = 0; i < nums.size(); ++i) {
int complement = target - nums[i];
auto it = seen.find(complement);
if (it != seen.end()) {
return {it->second, i};
}
seen[nums[i]] = i;
}
return {};
}
// Find duplicates in O(n)
template<typename T>
std::vector<T> find_duplicates(const std::vector<T>& items) {
std::unordered_set<T> seen;
std::vector<T> duplicates;
for (const auto& item : items) {
if (!seen.insert(item).second) {
duplicates.push_back(item);
}
}
return duplicates;
}
// Memoization / caching
class FibCache {
std::unordered_map<int, long long> cache;
public:
long long fib(int n) {
if (n <= 1) return n;
auto it = cache.find(n);
if (it != cache.end()) return it->second;
long long result = fib(n - 1) + fib(n - 2);
cache[n] = result;
return result;
}
};
// Group anagrams
std::vector<std::vector<std::string>>
group_anagrams(const std::vector<std::string>& words) {
std::unordered_map<std::string, std::vector<std::string>> groups;
for (const auto& word : words) {
std::string key = word;
std::sort(key.begin(), key.end());
groups[key].push_back(word);
}
std::vector<std::vector<std::string>> result;
for (auto& [_, group] : groups) {
result.push_back(std::move(group));
}
return result;
}Common Mistakes
Assuming iteration order. Elements in unordered containers have no guaranteed order. The order may even change after insertions that trigger rehashing. Never rely on iteration order.
Using lower_bound/upper_bound. These methods don't exist on unordered containers — they require sorted data. If you need range queries, use std::map/std::set instead.
Missing hash or equality for custom types. If you use a custom type as a key without providing std::hash specialization and operator==, you'll get a compile error. Both are required.
Bad hash functions. A hash function that returns the same value for many keys (e.g., return 0;) degrades the hash table to a linked list — O(n) for every operation. Ensure your hash distributes keys uniformly.
Not reserving capacity. Inserting into an unordered container without .reserve() causes multiple rehashes as the container grows, each copying all elements. If you know the approximate size, reserve upfront.
Summary
unordered_map and unordered_set are hash-table-based containers providing O(1) average-case lookups, insertions, and deletions. They require a hash function and equality operator for their key type. Pre-allocate with .reserve() and tune .max_load_factor() for performance. Choose them over sorted containers when you don't need ordered iteration or range queries. In the next lesson, you'll learn about container adapters — stack, queue, and priority_queue — which wrap containers to provide restricted LIFO, FIFO, and heap interfaces.